
Wenn Unternehmenskontext zum Unterscheidungsmerkmal wird, wird die Kontrollschicht strategisch.
Als ich über den Databricks Data + AI Summit in San Francisco lief, hatte ich erwartet, drei Tage lang über KI-Modelle nachzudenken.
Stattdessen kam ich nach Hause und dachte über Kontrolle nach.
Das hat mich überrascht.
In den vergangenen zwei Jahren begann nahezu jedes ernsthafte Gespräch über KI im Unternehmen mit denselben Fragen.
Welches Modell ist das beste? GPT, Claude, Gemini oder Llama? Offen oder geschlossen? Größere Kontextfenster oder niedrigere Inferenzkosten? Bessere Schlussfolgerungen oder geringere Latenz?
Diese Fragen sind nach wie vor wichtig. Sie werden es bleiben. Doch nach dem Summit erschienen sie mir nicht mehr als die Fragen, die darüber entscheiden, woher der langfristige Wettbewerbsvorteil eines Unternehmens kommt.
Die wichtigste Erkenntnis, die ich mitnahm, war nicht, dass KI-Modelle immer leistungsfähiger werden.
Das weiß jeder.
Es war die Erkenntnis, dass die Intelligenz des Modells nicht länger der einzige Engpass ist.
Der interessantere Engpass ist der Unternehmenskontext.
Während des Summits brachte es Databricks-CEO Ali Ghodsi auf den Punkt: KI habe kein Intelligenzproblem, sondern ein Kontextproblem. Wenn ein CFO die KI nicht dazu bringen kann zu erklären, warum sich die Margen verändert haben, dann ist das eine Kontextlücke, keine Modelllücke. Er ordnete den weiteren Weg entlang vier Prioritäten ein – Kontext, Kosten, Kontrolle und Wahlfreiheit – und dieser Rahmen ist mir geblieben.
Das klingt einfach.
Ist es nicht.
Unternehmenskontext ist kein Stapel von Dokumenten. Er ist keine Vektordatenbank. Er ist kein größeres Prompt-Fenster.
Unternehmenskontext ist Identität. Berechtigungen. Richtlinien. Prüfprotokolle. Gedächtnis. Werkzeugzugriff. Freigabeprozesse. Sicherheitsgrenzen. Kostenkontrollen. Datenherkunft. Compliance-Anforderungen. Menschliche Verantwortung.
Mit anderen Worten: Kontext ist all das, was nicht nur bestimmt, was ein KI-System weiß, sondern wie es sich innerhalb einer Organisation verhalten darf.
Sobald ich Kontext auf diese Weise zu begreifen begann, ließ sich eine weitere Frage nicht mehr ignorieren:
Wenn Kontext zur knappen Ressource der Unternehmens-KI wird – wer kontrolliert dann die Infrastruktur rund um diesen Kontext?
Diese Frage veränderte, wie ich alles andere deutete, was ich sah.
Rund um den Summit stellte Databricks Omnigent vor, ein Open-Source-Projekt, das es als Meta-Harness für KI-Agenten beschreibt: eine Schicht oberhalb einzelner Agenten wie Claude Code, Codex, Pi oder eigener Agenten, die diese über eine gemeinsame Schnittstelle zusammenführt, steuert und teilbar macht.[1]
Zunächst hielt ich es für eine weitere interessante Open-Source-Ankündigung.
Ich habe mich geirrt.
Je länger ich darauf blickte, desto deutlicher schien es auf eine umfassendere architektonische Verschiebung hinzuweisen.
Nicht, weil Omnigent selbst zwangsläufig die endgültige Antwort wäre.
Das ist es mit ziemlicher Sicherheit nicht.
Sondern weil es einem Problem einen Namen und eine Gestalt gibt, das Unternehmen erst ansatzweise zu verstehen beginnen.
Das Problem ist nicht länger nur die Modellabhängigkeit.
Es ist die Abhängigkeit von der Kontrollschicht.
Jede Technologiewelle bringt eine neue Kontrollschicht hervor.
Technologie verharrt nicht auf der Ebene, auf der die ersten Durchbrüche geschehen.
Sie wandert im Stack nach oben.
Großrechner wichen Servern. Server wurden virtualisiert. Virtuelle Maschinen wurden zu Cloud-Infrastruktur. Cloud-Infrastruktur schuf den Bedarf nach Orchestrierung. Orchestrierung schuf den Bedarf nach Kubernetes, Terraform, Identitätssystemen, Observability-Plattformen und Governance-Schichten.
Jedes Mal, wenn die darunterliegende Schicht standardisierter, austauschbarer und reichlicher verfügbar wird, verlagert sich der strategische Wert nach oben.
Dasselbe Muster zeichnet sich nun in der Unternehmens-KI ab.
Die erste Phase der aktuellen KI-Welle war modellzentriert.
Das war unvermeidlich. Die Foundation-Modelle waren der Durchbruch. Sie erzeugten den Schock. Sie erzeugten die Dringlichkeit. Sie erzeugten die Aufmerksamkeit der Führungsetagen.
Aber ein Modell für sich genommen ist kein Unternehmenssystem.
Ein Modell weiß nicht, auf welche Kundendaten es zugreifen darf.
Es weiß nicht, welches Repository es verändern darf.
Es weiß nicht, ob ein Werkzeugaufruf eine rechtliche Freigabe erfordert.
Es weiß nicht, welche interne Richtlinie in Deutschland gilt, in den Vereinigten Staaten aber nicht.
Es weiß nicht, wann Kosten, Risiko oder Compliance Vorrang vor Autonomie haben sollten.
All das liegt außerhalb des Modells.
Und je leistungsfähiger Agenten werden, desto wichtiger wird die umgebende Schicht.
Deshalb glaube ich, dass die Branche in eine zweite Phase eintritt.
Die erste Phase drehte sich um Intelligenz.
Die zweite Phase dreht sich um Kontrolle.
Das Modell wird leichter austauschbar. Das umgebende System nicht.
Es ist verlockend zu glauben, das eigentliche Souveränitätsproblem der KI sei der Modellanbieter.
In vielen Fällen ist er das nach wie vor.
Wenn Ihre gesamte KI-Strategie von einem geschlossenen Modell, einer API, einem Preismodell und der Roadmap eines einzigen Anbieters abhängt, dann haben Sie ein Abhängigkeitsproblem.
Aber das ist inzwischen nur die halbe Geschichte.
Die führenden Modelle nähern sich einander an. Open-Source-Alternativen verbessern sich rasch. Modell-Routing wird gängiger. Unternehmen entwerfen zunehmend Systeme, die für unterschiedliche Aufgaben unterschiedliche Modelle aufrufen können.
Mit anderen Worten: Die Modellschicht wird austauschbarer.
Nicht vollkommen. Nicht überall. Aber der Richtung nach ja.
Die schwierigere Abhängigkeit entsteht möglicherweise eine Schicht oberhalb des Modells: beim Agent-Harness.
Ein Agent-Harness ist die Softwareschicht, die ein rohes Modell in etwas verwandelt, das handeln kann. Sie gibt dem Modell Werkzeuge, Dateien, Gedächtnis, Ausführungsumgebungen, Berechtigungen, Arbeitsabläufe und Leitplanken. Es ist der Unterschied zwischen einem Sprachmodell, das eine Frage beantworten kann, und einem Agenten, der ein Repository öffnen, Code prüfen, Dateien schreiben, Tests ausführen und einen Pull Request einreichen kann.
In dieser Schicht verbringen immer mehr Entwicklerinnen, Entwickler und Unternehmen inzwischen ihre Zeit.
Claude Code, Codex, Cursor, Pi, OpenCode und ähnliche Werkzeuge sind nicht bloß Oberflächen.
Sie werden zu Arbeitsumgebungen für KI-Arbeit.
Und sobald Arbeit in eine Arbeitsumgebung wandert, sammeln sich Wechselkosten rasch an.
Aus Ihren Prompts werden Arbeitsabläufe. Aus Arbeitsabläufen werden Gewohnheiten. Aus Gewohnheiten werden Teamprozesse. Aus Teamprozessen werden Governance-Annahmen.
Irgendwann ist das Werkzeug nicht mehr nur ein Werkzeug.
Es ist Teil Ihrer Architektur.
Der Juni machte das Risiko greifbar.
Zwei Ereignisse in diesem Juni ließen das Abhängigkeitsproblem weniger theoretisch erscheinen.
Das erste geschah auf der Modellschicht.
Am 12. Juni 2026 erklärte Anthropic, eine Exportkontroll-Anordnung der US-Regierung verpflichte das Unternehmen, den Zugang zu Fable 5 und Mythos 5 für ausländische Staatsangehörige auszusetzen; in der Praxis seien dadurch beide Modelle abrupt deaktiviert worden – darunter Fable 5, das öffentlich verfügbare Modell, auf dem Teams aktiv aufbauten – und zwar für alle Kundinnen und Kunden, um die Vorgaben einzuhalten.[2]
Über die Einzelheiten dieser Entscheidung wird man streiten.
Die architektonische Lehre ist eindeutiger.
Ein Modell kann über Nacht aus der Produktionsplanung verschwinden.
Nicht, weil die Technologie aufhörte zu funktionieren.
Nicht, weil das nutzende Unternehmen eine schlechte technische Entscheidung getroffen hätte.
Sondern weil die Abhängigkeit in einem rechtlichen, geopolitischen und anbieterkontrollierten Umfeld saß, das der Kunde nicht beherrschte.
Das zweite Ereignis geschah eine Schicht darüber.
Am 10. April 2026 kündigte das Unternehmen hinter Vibe Kanban an, den Betrieb einzustellen, während das Projekt als Open Source und von der Community gepflegt weiterlaufen solle.[3] Das GitHub-Repository zeigte bei meiner Prüfung noch über 27.000 Sterne – doch seit Ende April gab es keine Commits mehr; Community-Pflege dem Namen nach, kaum der Sache nach. Die Ankündigung machte eines klar: Popularität ist keine Governance.[4]
Siebenundzwanzigtausend GitHub-Sterne garantieren keine Anbieterkontinuität.
Sie garantieren kein Geschäftsmodell. Sie garantieren keine Wartung. Sie garantieren keine Belastbarkeit auf Unternehmensniveau.
Das ist keine Kritik an Vibe Kanban. Open-Source-Projekte entwickeln sich weiter, Unternehmen scheitern, Communities übernehmen, und Software überdauert oft ihre ursprünglichen Schöpfer.
Der Punkt ist architektonischer Natur.
Unternehmen beginnen, kritische Arbeitsabläufe auf Werkzeugen aufzubauen, deren langfristiges Kontrollmodell oft unklar ist.
Ein Modell kann verschwinden. Ein Harness kann ins Stocken geraten. Ein Anbieter kann die Richtung wechseln. Eine Lizenz kann sich ändern. Ein Cloud-Dienst kann abgeschaltet werden. Eine Roadmap kann aufhören, zu Ihren Bedürfnissen zu passen.
Die Abhängigkeit in der Unternehmens-KI besteht inzwischen auf zwei unabhängigen Schichten:
- Die Modellschicht – die Intelligenz, die Sie aufrufen.
- Die Harness-Schicht – die Umgebung, die Intelligenz in Handlung verwandelt.
Die meisten Unternehmen sind sich der ersten bewusst.
Weit weniger sind auf die zweite vorbereitet.

Die Antwort lautet nicht: den richtigen Anbieter wählen.
Eine verbreitete Reaktion auf das Abhängigkeitsrisiko ist die Suche nach dem sichersten Anbieter.
Das ist verständlich.
Es genügt aber nicht.
Es gibt keinen dauerhaft sicheren Anbieter.
Es gibt nur Architekturen, die einen Wechsel mehr oder weniger teuer machen.
Das ist die strategische Frage, die Unternehmen sich stellen sollten:
Wenn sich das Modell ändert – was bricht? Wenn sich der Harness ändert – was bricht? Wenn der Anbieter seine Roadmap ändert – was bricht? Wenn ein Werkzeug verschwindet – was können wir noch bewahren?
Das Ziel ist nicht, das siegreiche Modell vorherzusagen.
Das Ziel ist, auf Umkehrbarkeit hin zu entwerfen.
Das erfordert, Governance von Ausführung zu trennen.
Es erfordert, Richtlinien, Berechtigungen, Gedächtnis, Prüfbarkeit und Kostenkontrollen außerhalb eines einzelnen Modells oder Harness zu halten.
Es erfordert eine Architektur, in der das Unternehmen die Kontrolle behält, auch wenn sich das darunterliegende Ökosystem verändert.
Hier wird der Gedanke eines Meta-Harness interessant.
Nicht als Schlagwort. Nicht als weitere Kategorie-Folie. Sondern als architektonische Antwort auf ein reales Abhängigkeitsproblem.
Ein Meta-Harness ist eine Kontrollschicht oberhalb einzelner Agent-Harnesses.
Er ersetzt nicht Claude Code, Codex, Cursor, Pi oder eigene Agenten.
Er sitzt über ihnen.
Sein Zweck ist es, Agenten kombinierbar, steuerbar und austauschbar zu machen.
Ein vereinfachter Stack sieht so aus:

Das Foundation-Modell liefert das Schlussfolgern.
Der Harness verwandelt Schlussfolgern in Handeln.
Die Kontrollschicht bestimmt, welche Handlungen unter welchen Bedingungen, mit welchen Werkzeugen, unter welchen Kostengrenzen und mit welchem Prüfprotokoll erlaubt sind.
In dieser Schicht siedelt sich Souveränität zunehmend an. Und hier wird Unternehmenskontext – Identität, Berechtigungen, Gedächtnis, Prüfprotokolle – entweder über Werkzeuge hinweg bewahrt oder in einem einzigen gefangen.
Warum die Kontrollschicht wichtiger ist als das Etikett.
Ich halte den Begriff Meta-Harness nicht für besonders wichtig.
Die Kategorie wird am Ende vielleicht anders heißen. Agent Control Plane. AI-Operations-Schicht. Agent-Governance-Schicht. Enterprise Agent OS.
Der Name ist weniger wichtig als die Rolle.
Die Rolle besteht darin, zu verhindern, dass Unternehmenskontext und Governance in einer einzigen Agentenumgebung gefangen sind.
Das ist deshalb wichtig, weil das Agenten-Ökosystem fragmentiert.
Verschiedene Teams werden verschiedene Werkzeuge nutzen. Entwicklerinnen und Entwickler bevorzugen vielleicht Claude Code oder Cursor. Datenteams nutzen womöglich Databricks-eigene Agenten. Fachanwenderinnen und Fachanwender interagieren mit aufgabenspezifischen Copiloten. Sicherheitsteams verlangen Richtliniendurchsetzung. Compliance-Teams verlangen Protokolle und Prüfbarkeit. Finanzteams verlangen Kostenkontrollen. Die IT verlangt Identitätsintegration.
Kein einzelner Harness wird all diese Bedürfnisse über ein Unternehmen hinweg erfüllen.
Aber die Richtlinien, die sie regeln, sollten nicht für jedes Werkzeug neu erfunden werden.
Das ist der Kerngedanke.
Ein Unternehmen sollte Governance nicht jedes Mal neu aufbauen, wenn ein neuer Agent erscheint.
Es sollte Agenten über eine Schicht regeln, die es selbst kontrolliert.
Der Markt bewegt sich bereits in diese Richtung.
Nach dem Summit habe ich acht aufkommende Lösungen an einer einzigen Frage gemessen:
Welche Architektur lässt ein Unternehmen am unabhängigsten, falls sich Modelle, Anbieter oder Agenten-Frameworks morgen ändern?
Bewusst begann ich nicht mit den üblichen Fragen. Nicht: Welches Werkzeug hat die beste Demo? Nicht: Welches Projekt hat die meisten Sterne? Nicht: Welcher Anbieter hat den geschliffensten Pitch? Nicht: Welches Produkt wirkt derzeit am reifsten?
Stattdessen habe ich auf architektonische Freiheit geschaut.
Lässt es sich selbst hosten? Lässt es sich forken? Kann es über mehrere Modelle hinweg laufen? Funktioniert es über mehrere Harnesses hinweg? Sind Richtlinien ausgelagert oder in Prompts eingebettet? Ist die Ausführung isoliert? Bewahrt es die Prüfbarkeit? Senkt es die Wechselkosten? Hält es Governance portabel?
Die Ergebnisse waren weniger wichtig als das Muster.
Der Markt konvergiert nicht auf eine Implementierung.
Er konvergiert auf einen architektonischen Gedanken:
Trenne die Unternehmenskontrolle von der Agentenausführung.
Verschiedene Plattformen drücken diesen Gedanken unterschiedlich aus. Einige optimieren für operative Reife. Einige für Offenheit. Einige für die Entwicklererfahrung. Einige für Richtliniendurchsetzung. Einige eignen sich besser für Coding-Agenten. Andere stehen der Orchestrierung von Unternehmensabläufen näher.
Genau das ist von einer jungen Kategorie zu erwarten.
Die Grundbausteine bilden sich noch. Das Vokabular ist noch instabil. Die Gewinner stehen nicht fest.
Aber die Richtung wird klarer.
Konkret reichten die acht von verwaltet und reif – AWS Bedrock AgentCore – bis offen und schnelllebig: Omnigent, agentgateway, Preloop und Bernstein. Bei der reinen Unabhängigkeit lagen die offenen, selbst hostbaren Optionen vorn, wobei Omnigent am höchsten abschnitt – obgleich es noch ein frühes Projekt im Alpha-Stadium ist, das ich eher pilotieren als heute schon produktiv einsetzen würde. agentgateway, inzwischen unter dem Dach der Linux Foundation, war am stärksten auf der Governance- und Gateway-Schicht, die darunter liegt.
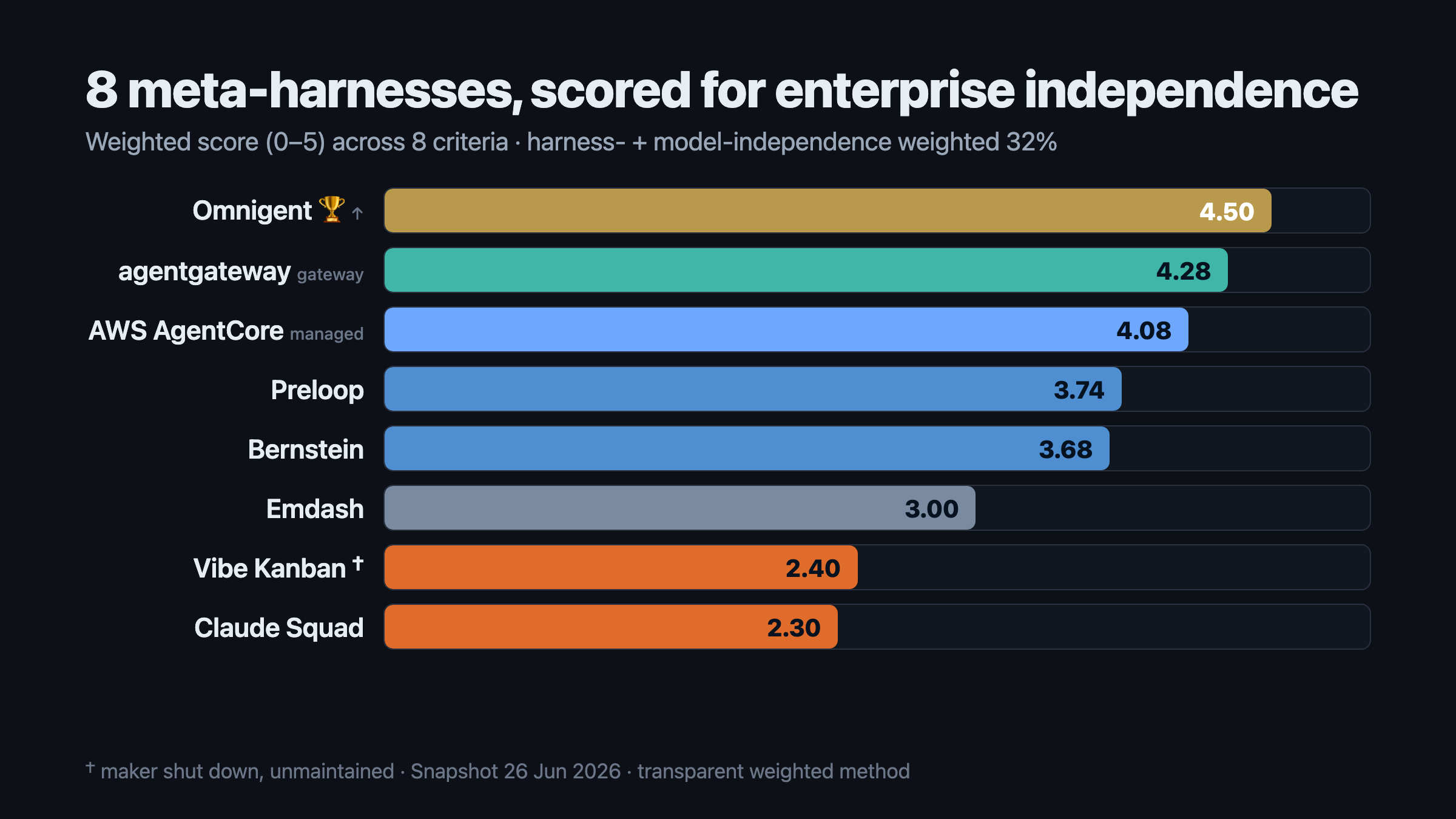
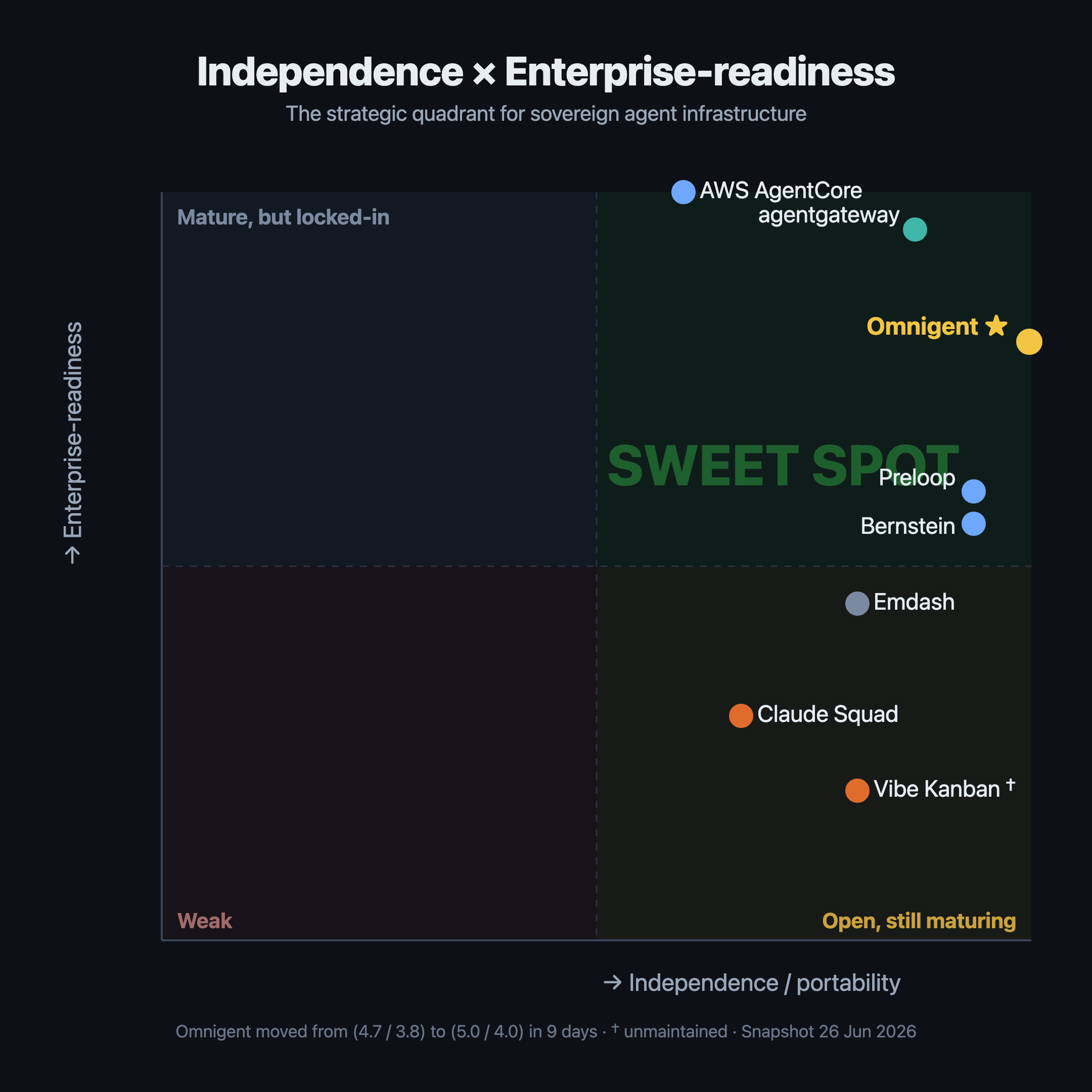

Omnigent ist in dieser Landschaft interessant, weil es sich ausdrücklich als Schicht oberhalb bestehender Agenten versteht, nicht als Ersatz für sie alle. Databricks beschreibt es als Open Source, Apache 2.0, mit Fokus auf Komposition, Richtlinien, Zusammenarbeit, Sandboxing und Multi-Harness-Betrieb.[1][5]
Das macht es zu einem nützlichen Signal.
Aber die größere Geschichte ist nicht Omnigent.
Die größere Geschichte ist, dass der Bedarf nach dieser Schicht offensichtlich wird.
Die Unternehmensfrage verändert sich.
Jahrelang lautete die strategische KI-Frage:
Welches Modell sollten wir nutzen?
Dann wurde sie zu:
Welche Anwendungen können wir auf KI aufbauen?
Die nächste Frage ist grundlegender:
Welcher Schicht vertrauen wir die Kontrolle über KI im Unternehmen an?
Das ist eine Frage auf CIO-Ebene.
Sie ist nicht nur eine Data-Science-Frage. Sie ist nicht nur eine Frage der Entwicklerwerkzeuge.
Sie berührt Architektur, Sicherheit, Compliance, Beschaffung, Infrastruktur und digitale Souveränität.
Denn sobald Agenten vom Experiment in operative Arbeitsabläufe übergehen, hören sie auf, isolierte Produktivitätswerkzeuge zu sein.
Sie werden Teil des unternehmerischen Nervensystems: Sie lesen und schreiben, rufen Werkzeuge auf, treffen Entscheidungen, verändern Systeme und beeinflussen Arbeitsabläufe – und erzeugen dabei reale Kosten und reales Risiko.
An diesem Punkt brauchen Unternehmen mehr als Modellzugang.
Sie brauchen Kontrollflächen. Sie brauchen Prüfbarkeit. Sie brauchen Ausstiegswege. Sie brauchen Portabilität von Richtlinien. Sie brauchen die Fähigkeit, Komponenten auszutauschen, ohne das gesamte Betriebsmodell neu zu bauen.
Kurz gesagt:
Sie brauchen eine KI-Ausstiegsstrategie.
Digitale Souveränität wird architektonisch, nicht rhetorisch.
Digitale Souveränität wird oft in politischen oder regulatorischen Begriffen diskutiert.
Wo werden die Daten gespeichert? Welche Rechtsordnung gilt? Welcher Cloud-Anbieter ist akzeptabel? Welches Modell ist europäisch, amerikanisch oder chinesisch?
Diese Fragen sind wichtig.
Aber sie genügen nicht.
Souveränität ist auch architektonisch.
Ein Unternehmen ist nicht souverän, weil es einmal ein Open-Source-Modell gewählt hat. Es ist nicht souverän, weil es einmal etwas auf der eigenen Cloud betrieben hat. Es ist nicht souverän, weil ein Anbietervertrag eine Ausstiegsklausel enthält.
Es wird souveräner, wenn es Anbieter, Modelle, Harnesses und Betriebsumgebungen wechseln kann, ohne die Governance, den Kontext und das operative Wissen zu verlieren, die das System wertvoll machen.
Deshalb ist die Kontrollschicht wichtig.
Die Kontrollschicht ist der Ort, an dem Unternehmens-KI entweder portabel bleibt oder gefangen wird.
Wenn Ihre Governance bei einem einzigen Modellanbieter liegt, sind Sie nicht portabel. Wenn Ihre Arbeitsabläufe in einem einzigen Harness liegen, sind Sie nicht portabel. Wenn Ihre Richtlinien als Prompt-Fragmente über Werkzeuge verstreut sind, sind Sie nicht portabel. Wenn Ihr Prüfprotokoll vom Dashboard eines einzigen Anbieters abhängt, sind Sie nicht portabel.
Portabilität muss entworfen werden.
Sie lässt sich nicht am Ende hinzufügen.
Was ich jetzt als Unternehmen täte.
Würde ich heute eine KI-Architektur für ein Unternehmen entwerfen, würde ich nicht versuchen, den endgültigen Sieger im Modellrennen zu küren.
Ich würde vom Gegenteil ausgehen: dass sich Modelle und Agentenwerkzeuge weiter verändern, dass manche Anbieter verschwinden und manche Open-Source-Projekte ins Stocken geraten, und dass regulatorische und geopolitische Zwänge nur wichtiger werden – nicht weniger. Dann würde ich die Architektur entsprechend gestalten.
Das bedeutet dreierlei.
Erstens: Trennen Sie das Modell von der Governance-Schicht. Lassen Sie die Modellwahl nicht über Ihre Richtlinien, Ihre Prüfbarkeit oder Ihr Berechtigungsmodell bestimmen.
Zweitens: Trennen Sie den Agent-Harness vom Unternehmenskontext. Lassen Sie nicht zu, dass ein einziges Werkzeug der einzige Ort wird, an dem Arbeitsabläufe, Gedächtnis und Berechtigungen existieren.
Drittens: Bauen oder übernehmen Sie eine Kontrollschicht, die Modelle und Harnesses als austauschbare Komponenten behandelt.
Nicht, weil ein Austausch einfach wäre.
Sondern weil ein Austausch möglich bleiben sollte.
Unternehmen, die das früh verstehen, werden später mehr Freiheit haben.
Unternehmen, die es ignorieren, finden sich womöglich mit beeindruckenden KI-Demos und fragiler KI-Infrastruktur wieder.
Die eigentliche Verschiebung.
Die eigentliche Verschiebung in der Unternehmens-KI ist nicht der Übergang von geschlossenen zu offenen Modellen. Sie ist nicht der Übergang von Chatbots zu Agenten. Sie ist nicht einmal der Übergang von einzelnen Agenten zu Multi-Agenten-Systemen.
Das ist alles wichtig, aber es sind Symptome.
Die tiefere Verschiebung ist diese:
KI wird von einer Fähigkeit zur Infrastruktur.
Und wenn eine Technologie zur Infrastruktur wird, verändert sich stets die strategische Frage.
Nicht einfach:
Was kann sie?
Sondern:
Wer kontrolliert sie?
Deshalb kam ich vom Summit nach Hause und dachte weniger über Modelle nach und mehr über Kontrolle.
Bessere Modelle werden zählen. Bessere Benchmarks werden zählen. Bessere Agenten werden zählen.
Aber im Unternehmen kommt der bleibende Vorteil womöglich aus etwas weniger Sichtbarem:
aus der Architektur, die den Kontext geregelt, die Agenten austauschbar und die strategische Freiheit intakt hält.
Jedes Unternehmen hat bereits eine Cloud-Strategie.
Jedes Unternehmen braucht nun eine KI-Ausstiegsstrategie.
Andernfalls hat es eigentlich gar keine KI-Strategie.
Quellen
- [1] Databricks, „Introducing Omnigent: A Meta-Harness to Combine, Control and Share Your Agents“, 13. Juni 2026. databricks.com
- [2] Anthropic, „Statement on the US government directive to suspend access to Fable 5 and Mythos 5″, 12. Juni 2026. anthropic.com
- [3] Vibe Kanban, „Goodbye bloop“, 10. April 2026. vibekanban.com
- [4] BloopAI/vibe-kanban, GitHub-Repository, abgerufen am 26. Juni 2026. github.com
- [5] Omnigent, GitHub-Repository, abgerufen am 26. Juni 2026. github.com
